在之前的文章中,我们介绍了三类基础知识蒸馏算法以及知识蒸馏的迁移学习应用。今天我们一起来学习如何使用 MMRazor 实现知识蒸馏。
MMRazor 是 OpenMMLab 生态的面向模型压缩的开源算法库,目前主要涵盖了知识蒸馏、剪枝、NAS 三类算法,近期会进一步支持一系列模型量化算法。
我们接下来将从 MMRazor 知识蒸馏框架介绍,基于 MMRazor 的知识蒸馏实战教程两个方面展开分享。
MMRazor 知识蒸馏框架介绍
知识蒸馏(Knowledge Distillation,简记为 KD)是一种经典的模型压缩方法,核心思想是通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型(或多模型的 ensemble),在不改变学生模型结构的情况下提高其性能。2015 年 Hinton 团队提出的基于“软标签”(response-based)的知识蒸馏技术(一般将该文算法称为vanilla-KD)掀起了相关研究热潮,其后基于“特征”(feature-based)和基于“关系”(relation-based)的KD算法被陆续提出。
由于知识蒸馏的过程可以理解为一个,获取学生网络和教师网络指定蒸馏位点的输出特征并计算蒸馏 loss 的过程。因此,实现一个蒸馏算法往往会有以下几点需求:
- 获取学生网络和教师网络指定蒸馏位点的输出特征,例如某个 nn.Module,某个类方法或是某个函数的输入输出信息。在 MMRazor 中,我们通过 Recorder 组件实现。
- 在学生网络前向传播过程中,某一中间输出需要被教师网络对应输出覆盖。例如,在 LAD 中,学生网络训练过程中需要使用教师网络的 label assign 结果覆盖掉自身结果。在 MMRazor 中,我们通过 Deliver 组件实现。
- 一个蒸馏算法中可能会有多个蒸馏 loss 联合作用。而某个蒸馏 loss 需要的输入可能来自于不同 recorder,也可能来自于某一个 recorder 获取的多个数据中的若干个。因此,我们需要利用 loss_forward_mappings 数据结构从 Recorder 获取的输出特征中筛选得到蒸馏 loss 需要的部分,并利用 connectors 模块进行后处理(例如,对于 feature-base 的方法,当学生和教师网络输出特征维度不同时,往往会对学生网络对应特征进行后处理以保证蒸馏 loss 正确计算)。在 MMRazor 中,这一系列功能我们通过 ConfigurableDistiller 来统一管理。
- 进一步,为了解决特定问题或面向特定场景,知识蒸馏算法本身又可以细分为 data-free KD、online KD、self KD(可视为一种特殊的 online KD)和比较经典的 offline KD 等等。在 MMRazor中,我们通过设计不同的high level 的 Algorithm 组件以支持不同类型的蒸馏算法对应的 pipeline。
上述 4 个组件在 MMRazor 中的位置如下图所示。接下来,我们会详细介绍各个组件的设计动机和使用方法。
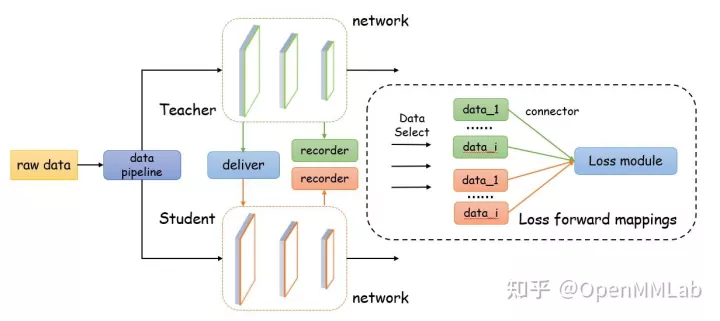
Recorder
如下图所示,Recorder 是一个上下文管理器,用于在模型前项传播过程中记录各种中间结果。同时,它还可以用来获取一些特定位点的数据,用于可视化分析或其他你想要的功能。为了适应更多的需求,我们在 MMRazor 中实现了多种类型的 Recorder 来获得不同类型的中间结果,它们由 RecorderManager 统一管理。
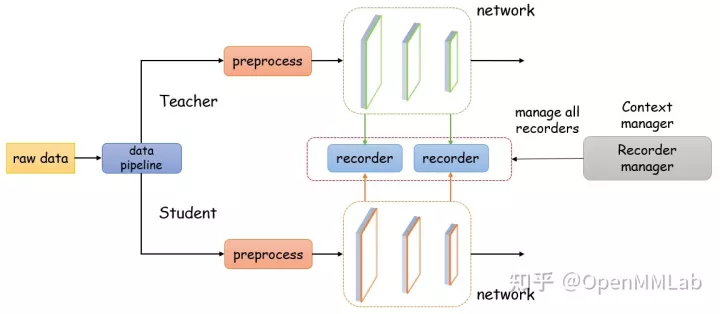
目前,我们支持了 7 类 Recorder,如下表所示:
| Recorder 名称 | 描述 |
|---|---|
| ModuleOutputsRecorder / ModuleInputsRecorder | 获取某个 torch.nn.Module 的 输出 / 输入 结果 |
| FunctionOutputsRecorder / FunctionInputsRecorder | 获取模型中使用到的某个函数的 输出 / 输入 结果 |
| MethodOutputsRecorder / MethodInputsRecorder | 获取模型中某个类的某个方法的 输出 / 输入 结果 |
| ParameterRecorder | 获取某个 torch.nn.Module 的模型参数 |
接下来我们以 ModuleOutputsRecorder 为例,为大家介绍下 Recorder 的使用方法。
ModuleOutputsRecorder
获取 nn.Module 的输入输出相对会比较容易,因为可以通过为 nn.Module 挂上 PyTorch 原生的 forward hook 来实现。由于这两种 Recorder 的使用方法非常类似,我们以 ModuleOutputsRecorder 为例来介绍它们是如何工作的:
1 | import torch |
注意,所有的 Recorder 在使用前都需要执行 initialize 方法
RecorderManager
RecorderManager 同样是上下文管理器,可用于管理各种类型的 Recorder。
在 RecorderManager 的帮助下,我们可以用尽可能少的代码管理几个不同的记录器,这减少了出错的可能性。
1 | import random |
Deliver
Deliver 工具是 MMRazor 专门为处理蒸馏算法中涉及的一些特殊情况而设计的,它在教师模型和学生模型之间转移并覆盖掉一些中间结果,如下图所示:
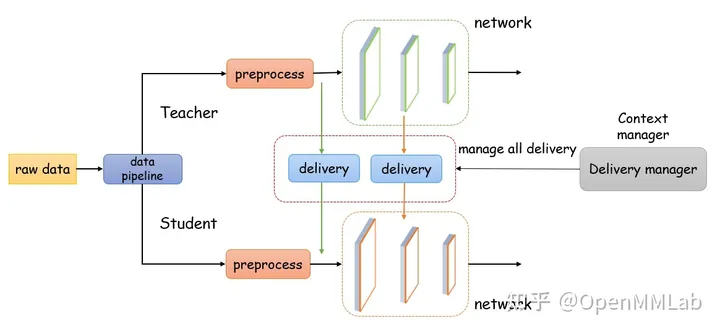
Deliver 并不像 Recorder 那样,基本在每个蒸馏算法中都会使用,但对于一些算法,它是必不可少的。例如,在 LAD 中,学生网络需要直接获取教师网络的 label assignment 信息,我们可以如下配置 Deliver:
1 | distill_deliveries = ConfigDict( |
Deliver 的可配置性,让我们可以不需要对源代码进行 hardcode 修改。
ConfigurableDistiller
ConfigurableDistiller 是一个功能强大的工具,可以在不修改教师或学生模型代码的情况下实现大多数蒸馏算法。它可以通过 Recorder 以一种 hack 的方式获得模型的各种中间结果。同样,它可以使用 Delivery 以 hack 的方式使用老师的中间结果来覆盖学生的中间结果。
1 | class ConfigurableDistiller: |
这里的 student_recorders、teacher_recordersdistill_deliveries 上文刚刚介绍。distill_losses 是蒸馏时用到的蒸馏损失函数,可以是一个或多个。
这里引入了两个新概念:connectors 和 loss_forward_mappings
Connectors
知识蒸馏算法往往分为 reponse-based、feature-based 和 relation-based 三类。其中,feature-based 方法以教师模型特征提取器产生的中间层特征为学习对象,最简单的 L2 损失如下所示:
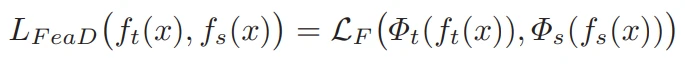
实现特征对齐功能的模块(上面提到的 phi_t 和 phi_s )是 feature-based KD 算法的核心模块(MMRazor 中称之为 connector),也是很多算法的重点研究对象。如针对教师 connector 进行预训练的 Factor Transfer 算法;以二值化形式筛选教师和学生原始特征的 AB 算法;将特征值转换为注意力值的 AT 算法等。OFD 对各相关算法进行总结,研究了特征位置、connector 的构成、损失函数等因素对蒸馏性能、信息损失的影响,汇总表如下所示:
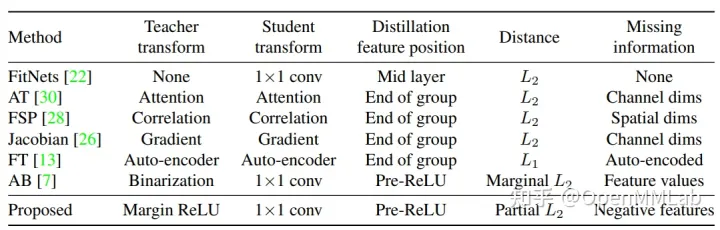
上面提到的 FitNets、Factor Transfer、AB、AT Loss(AT 算法与蒸馏最相关的损失计算部分)、OFD 等算法均被集成到了 MMRazor 算法库中,且核心模块 connector 被单独抽象出来作为可配置组件,非常便于大家进行“算法魔改”(如为 FitNets 算法配置上 Factor Transfer 的 connector 并计算 AT Loss)。
loss_forward_mappings
通过 Recorder 组件获得模型中间结果后,可以通过配置 loss_forward_mappings 来进一步指定不同的蒸馏 loss 的输入参数是什么。
下面代码表示我们只使用一个蒸馏 loss,我们把它称为 loss_neck,它实际上是一个 L2Loss,loss weight=5。我们分别设置 student_recorders 和 teacher_recorder 希望获取学生和教师网络的 ‘neck.gap’ 这一 module 的输出,输出特征命名为 feat。那么在配置 loss_forward_mappings 时可以看到 L2Loss 的 forward 方法有两个输入参数,分别为 s_feature 和 t_feature。而 s_feature 和 t_feature 又分别来自于名字为 feat 的学生和教师网络中间特征。
1 | distill_losses = dict( |
Algorithm
最后,Distill Algorithm 负责控制蒸馏的一整个 pipeline。MMRazor 实现了多类知识蒸馏算法,我们以最经典的,使用单个教师网络蒸馏单个学生网络的 SingleTeacherDistill 算法为例。下面代码展示了其在初始化时需要传入的参数:
1 | class SingleTeacherDistill: |
基于 MMRazor 的知识蒸馏实战教程
我们首先以 KD 算法使用 ResNet34 蒸馏 ResNet18 为例,介绍如何使用 MMRazor 实现基础蒸馏算法。
KD
步骤一:设计 Distiller 相关配置文件
传统 KD 算法的知识提取和 loss 计算过程非常简洁,只需获取学生网络和教师网络的输出 logits 并计算 KL 散度即可。Distiller 组件的配置文件主要分为四个部分,如下方代码所示。
1 | distiller=dict( |
- student_recorders 和 teacher_recorders 表示我们需要分别记录学生和教师网络中某一个 nn.Module 的输出,这个 nn.Module 的 module name 是 head.fc,记录的数据我们将其命名为 fc。
- 在整个蒸馏过程中,我们只使用了一种损失函数,因此 distill_losses 中只包含一组 key 和 value。key 是 loss_kl ,表示将这个蒸馏 loss 命名为 loss_kl,value 则是蒸馏 loss 对应的配置文件,表示我们用的蒸馏 loss 是 KLDivergence,超参数 temperature 温度为 1,loss weigh 为 5。
- loss_forward_mappings 指定每个 loss module 的输入数据是什么。在本示例中,loss module 有两个输入:preds_S 和 preds_T,分别表示学生和教师网络输出 logits,它们需要跟 KLDivergence loss module 中 forward 方法传入参数保持一致。另外,我们通过 from_student 和 recorder 两个字段判断从student_recorders 还是 teacher_recorders 中读取哪个值。dict(from_student=True, recorder=’fc’) 表示读取 student_recorders 中名字为 fc 的数据。
步骤二:设计 Algorithm 相关配置文件
算法层面需要进行以下配置。architecture 和 teacher 指定了学生/教师网络的网络配置,teacher_ckpt 指定教师网络的预训练权重的路径,如果使用 MMClassification 提供的预训练参数,也可直接在 teacher 对应的字典中的 pretrained 的值设为 True。其余配置只需按照默认设置,即:teacher_trainable=False 表示蒸馏过程中教师网络是不可学习的;teacher_norm_eval=True 表示蒸馏过程中教师网络的 norm module 全程都处在 eval 模式下;calculate_student_loss=True 表示学生网络除了受教师网络监督外,还受到 ground truth 的监督。
1 | model = dict( |
步骤三:设计其他配置文件
最后,我们还需要定义数据集、优化器等其他配置文件,这部分直接引入 MMClassification 定义好的配置文件即可,代码如下,其中 val_cfg 定义了蒸馏过程中 evaluation 的 pipeline:
1 | _base_ = [ |
OFD
接下来我们以 OFD 算法为例,介绍如何使用 MMRazor 实现稍微复杂一些的算法。
步骤一:设计 Distiller 相关配置文件
1 | distiller=dict( |
上方代码是 OFD 算法 distiller 部分对应的配置文件。student_recorders 和 teacher_recorders 与上述 KD 算法类似,分别获取学生和教师网络三个 nn.module 的输出并命名为 bb_1,bb_2,bb_3
distill_losses定义了三个蒸馏 loss,loss weight 分别为 0.25,0.5 和 1.0。与传统 KD 算法不同,connectors定义了 OFD 中用到的 connector 结构 —— convbn layer。前文介绍过,MMRazor 使用 connectors 模块实现特征对齐功能,即:在获取 loss module 所需输入数据后,输入 loss module 前,数据需要经过 connector 处理。
最后 loss_forward_mappings 也会比 KD 中复杂些,我们以下方代码为例。代码中 distill_losses定义了 名为 loss_1 的蒸馏损失函数对应的是 loss_weight=0.25 的 OFDLoss。其中 OFDLoss loss module 的输入参数有两个,分别是 s_feature 和 t_feature。s_feature 来自名为 bb_1 的 student_recorders ,需要经过名为 loss_1_sfeat 的 connector 进行特征后处理。从下方 connectors 部分的定义可知,名为loss_1_sfeat 的 connector 是一个 ConvModule,输入输出通道数分别为 32 和 64。同理可得 t_feature。
1 | student_recorders=dict(bb_1=dict(type='ModuleOutputs', source='backbone.layer2.0.bn1')) |
步骤二 / 三:设计 Algorithm 相关配置文件 / 设计其他配置文件
步骤二、三与传统 KD 算法类似。至此,我们通过修改配置文件实现了 OFD 算法。
总结
本文介绍了 MMRazor 对知识蒸馏算法的设计框架,并列举了两个简单例子来介绍如何使用 MMRazor 开发知识蒸馏算法。